Метод главных компонент. Факторный анализ. Метод главных компонент Интерпретация главных компонент
Метод главных компонент – это метод, который переводит большое количество связанных между собой (зависимых, коррелирующих) переменных в меньшее количество независимых переменных, так как большое количество переменных часто затрудняет анализ и интерпретацию информации. Строго говоря, этот метод не относится к факторному анализу, хотя и имеет с ним много общего. Специфическим является, во-первых, то, что в ходе вычислительных процедур одновременно получают все главные компоненты и их число первоначально равно числу исходных переменных; во-вторых, постулируется возможность полного разложения дисперсии всех исходных переменных, т.е. ее полное объяснение через латентные факторы (обобщенные признаки).
Например, представим, что мы провели исследование, в котором измерили у студентов интеллект по тесту Векслера, тесту Айзенка, тесту Равена, а также успеваемость по социальной, когнитивной и общей психологии. Вполне возможно, что показатели различных тестов на интеллект будут коррелировать между собой, так как они, в конце концов, измеряют одну характеристику испытуемого – его интеллектуальные способности, хотя и по-разному. Если переменных в исследовании слишком много (x 1 , x 2 , …, x p ) , а некоторые из них взаимосвязаны, то у исследователя иногда возникает желание уменьшить сложность данных, сократив количество переменных. Для этого и служит метод главных компонент, который создает несколько новых переменных y 1 , y 2 , …, y p , каждая из которых является линейной комбинацией первоначальных переменных x 1 , x 2 , …, x p :
y 1 =a 11 x 1 +a 12 x 2 +…+a 1p x p
y 2 =a 21 x 1 +a 22 x 2 +…+a 2p x p
… (1)
y p =a p1 x 1 +a p2 x 2 +…+a pp x p
Переменные y 1 , y 2 , …, y p называются главными компонентами или факторами. Таким образом, фактор – это искусственный статистический показатель, возникающий в результате специальных преобразований корреляционной матрицы . Процедура извлечения факторов называется факторизацией матрицы. В результате факторизации из корреляционной матрицы может быть извлечено разное количество факторов вплоть до числа, равного количеству исходных переменных. Однако факторы, определяемые в результате факторизации, как правило, не равноценны по своему значению.
Коэффициенты a ij , определяющие новую переменную, выбираются таким образом, чтобы новые переменные (главные компоненты, факторы) описывали максимальное количество вариативности данных и не коррелировали между собой. Часто полезно представить коэффициенты a ij таким образом, чтобы они представляли собой коэффициент корреляции между исходной переменной и новой переменной (фактором). Это достигается умножением a ij на стандартное отклонение фактора. В большинстве статистических пакетов так и делается (в программе STATISTICA тоже). Коэффициенты a ij Обычно они представляются в виде таблицы, где факторы располагаются в виде столбцов, а переменные в виде строк:
Такая таблица называется таблицей (матрицей) факторных нагрузок. Числа, приведенные в ней, являются коэффициентами a ij .Число 0,86 означает, что корреляция между первым фактором и значением по тесту Векслера равна 0,86. Чем выше факторная нагрузка по абсолютной величине, тем сильнее связь переменной с фактором.
При моделировании производственно-экономических процессов, чем ниже уровень рассматриваемой производственной подсистемы (структурного полразделения, исследуемого процесса), тем более характерна для входных параметров относительная независимость определяющих их факторов. При анализе основных качественных показателей работы предприятия (производительности труда, себестоимости продукции, прибыли и других показателей) приходится иметь дело с моделированием процессов со взаимосвязанной системой входных параметров (факторов). При этом процесс статистического моделирования систем характеризуется сильной коррелированностью, а в отдельных случаях почти линейной зависимостью определяющих факторов (входных параметров процесса). Это случай мультиколлинеарности, т.е. существенной взаимозависимости (коррелированности) входных параметров, модель регрессии здесь не отражает адекватно реального исследуемого процесса. Если использовать добавление или отбрасывание ряда факторов, увеличение или уменьшение объема исходной информации (количества наблюдений), то это существенно изменит модель исследуемого процесса. Применение такого подхода может резко изменить и величины коэффициентов регрессии, характеризующие влияние исследуемых факторов, и даже направление их влияния (знак при коэффициентах регрессии может измениться на противоположный при переходе от одной модели к другой).
Из опыта научных исследований известно, что большинство экономических процессов отличается высокой степенью взаимовлияния (интеркорреляции) параметров (изучаемых факторов). При расчетах регрессии моделируемых показателей по этим факторам возникают трудности в интерпретации значений коэффициентов в модели. Такая мультиколлинеарность параметров модели часто носит локальный характер, т. е. существенно связаны между собой не все исследуемые факторы, а отдельные группы входных параметров. Наиболее общий случай мультиколлинеарных систем характеризуется таким набором исследуемых факторов, часть из которых образует отдельные группы с сильно взаимосвязанной внутренней структурой и практически не связанных между собой, а часть представляет собой отдельные факторы, несформированные в блоки и несущественно связанные как между собой, так и с остальными факторами, входящими в группы с сильной интеркорреляцией.
Для моделирования такого типа процессов требуется решение проблемы о способе замены совокупности существенно взаимосвязанных факторов на какой-либо другой набор некоррелированных параметров, обладающий одним важным свойством: новый набор независимых параметров должен нести в себе всю необходимую информацию о вариации или дисперсии первоначального набора факторов исследуемого процесса. Эффективным средством решения такой задачи является использование метода главных компонент. При использовании этого метода возникает задача экономической интерпретации комбинаций исходных факторов, вошедших в наборы главных компонент. Метод позволяет уменьшить число входных параметров модели, что упрощает использование получаемых в результате регрессионных уравнений.
Сущность вычисления главных компонент заключается в определении корреляционной (ковариационной) матрицы для исходных факторов X j и нахождении характеристических чисел (собственных значений) матрицы и соответствующих векторов. Характеристические числа являются дисперсиями новых преобразованных переменных и для каждого характеристического числа соответствующий вектор дает вес, с которым старые переменные входят в новые. Главные компоненты – это линейные комбинации исходных статистических величин. Переход от исходных (наблюдаемых) факторов к векторам главных компонент осуществляется посредством поворота координатных осей.
Для регрессионного анализа используют, как правило, лишь несколько первых главных компонент, которые в сумме объясняют от 80 до 90 % всей исходной вариации факторов, остальные из них отбрасываются. В случае если все компоненты включены в регрессию, результат ее, выраженный через первоначальные переменные, будет идентичен множественному уравнению регрессии.
Алгоритм вычисления главных компонент
Допустим, имеется m векторов (исходных факторов) размерностью n (количество измерений), которые составляют матрицу Х:
Поскольку, как правило, основные факторы моделируемого процесса имеют разные единицы измерения (одни выражены в кг, другие – в км, третьи – в денежных единицах и т. д.), для их сопоставления, сравнения степени влияния, применяют операцию масштабирования и центрирования. Преобразованные входные факторы обозначим через y ij . В качестве масштабов выбираются чаще всего величины стандартных (среднеквадратических) отклонений:

где σ j – среднее квадратическое отклонение X j ; σ j 2 - дисперсия; - среднее значение исходных факторов в данной j-ой серии наблюдений
(Центрированной случайной величиной называется отклонение случайной величины от ее математического ожидания. Нормировать величину х – означает перейти к новой величине у, для которой средняя величина равна нулю, а дисперсия – единице).
Определим матрицу парных коэффициентов корреляции
![]()
где у ij – нормированное и центрированное значение x j –й случайной величины для i-го измерения; y ik – значение для k-й случайной величины.
Значение r jk характеризует степень разброса точек по отношению к линии регрессии.
Искомая матрица главных компонент F определяется из следующего соотношения (здесь используется транспонированная,- “повернутая на 90 0 ” – матрица величин y ij):

или используя векторную форму:

 ,
,
где F – матрица главных компонент, включающая совокупность n полученных значений для m главных компонент; элементы матрицы А являются весовыми коэффициентами, определяющими долю каждой главной компоненты в исходных факторах.
Элементы матрицы А находятся из следующего выражения
где u j – собственный вектор матрицы коэффициентов корреляции R; λ j – соответствующее собственное значение.
Число λ называется собственным значением (или характеристическим числом) квадратной матрицы R порядка m, если можно подобрать такой m-мерный ненулевой собственный вектор u, что Ru = λu.
Множество всех собственных значений матрицы R совпадает с множеством всех решений уравнения |R - λE| = 0. Если раскрыть определитель det |R - λE|, то получится характеристический многочлен матрицы R. Уравнение |R - λE| = 0 называется характеристическим уравнением матрицы R.

Пример определения собственных значений и собственных векторов. Дана матрица .
Ее характеристическое уравнение




Это уравнение имеет корни λ 1 =18, λ 2 =6, λ 3 =3. найдем собственный вектор (направление), соответствующее λ 3 . Подставляя λ 3 в систему, получим:
8u 1 – 6u 2 +2u 3 = 0
6u 1 + 7u 2 - 4u 3 = 0
2u 1 - 4u 2 + 3u 3 = 0
Т. к. определитель этой системы равен нулю, то согласно правилам линейной алгебры, можно отбросить последнее уравнение и решать полученную систему по отношению к произвольной переменной, например u 1 = с= 1
6 u 2 + 2u 3 = - 8c
7 u 2 – 4 u 3 = 6 c
Отсюда получим собственное направление (вектор) для λ 3 =3
1 таким же образом можно найти собственные вектора
Общий принцип, лежащий в основе процедуры нахождения главных компонент показан на рис. 29.
 |
Рис. 29. Схема связи главных компонент с переменными
Весовые коэффициенты характеризуют степень влияния (и направленность) данного “скрытого” обобщающего свойства (глобального понятия) на значения измеряемых показателей Х j .
Пример интерпретации результатов компонентного анализа:

Название главной компоненты F 1 определяется наличием в ее структуре значимых признаков Х 1 , Х 2 , Х 4 , Х 6 , все они представляют характеристики эффективности производственной деятельности, т.е. F 1 - эффективность производства .
Название главной компоненты F 2 определяется наличием в ее структуре значимых признаков Х 3 , Х 5 , Х 7, т.е. F 2 - это размер производственных ресурсов .
ЗАКЛЮЧЕНИЕ
В пособии даны методические материалы, предназначенные для освоения экономико-математического моделирования в целях обоснования принимаемых управленческих решений. Большое внимание уделено математическому программированию, включая целочисленное программирование, нелинейное программирование, динамическое программирование, задачам транспортного типа, теории массового обслуживания, методу главных компонент. Подробно рассмотрено моделирование в практике организации и управления производственными системами, в предпринимательской деятельности и финансовом менеджменте. Изучение представленного материала предполагает широкое использование техники моделирования и расчетов с использованием комплекса программ PRIMA и в среде электронной таблицы Excel.
Метод главных компонент (PCA - Principal component analysis) - один из основных способов уменьшить размерность данных при наименьшей потере сведений. Изобретенный в 1901 г. Карлом Пирсоном он широко применяется во многих областях. Например, для сжатия данных, «компьютерного зрения», распознавания видимых образов и т.д. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных. Метод главных компонент часто называют преобразованием Кархунена-Лёве (Karhunen-Loeve transform) или преобразованием Хотеллинга (Hotelling transform). Также над этим вопросом работали математики Косамби (1943 г.), Пугачёв (1953 г.) и Обухова (1954 г.).
Задача анализа главных компонент имеет своей целью аппроксимировать (приблизить) данные линейными многообразиями меньшей размерности; найти подпространства меньшей размерности, в ортогональной проекции на которые разброс данных (то есть среднеквадратичное отклонение от среднего значения) максимален; найти подпространства меньшей размерности, в ортогональной проекции на которые среднеквадратичное расстояние между точками максимально. В этом случае оперируют конечными множествами данных. Они эквивалентны и не используют никакой гипотезы о статистическом порождении данных.
Кроме того задачей анализа главных компонент может быть цель построить для данной многомерной случайной величины такое ортогональное преобразование координат, что в результате корреляции между отдельными координатами обратятся в ноль. Эта версия оперирует случайными величинами.
Рис.3
На приведённом выше рисунке даны точки P i на плоскости, p i - расстояние от P i до прямой AB. Ищется прямая AB, минимизирующая сумму
Метод главных компонент начинался с задачи наилучшей аппроксимации (приближения) конечного множества точек прямыми и плоскостями. Например, дано конечное множество векторов. Для каждого k = 0,1,...,n ? 1 среди всех k-мерных линейных многообразий в найти такое, что сумма квадратов уклонений x i от L k минимальна:
где? евклидово расстояние от точки до линейного многообразия.
Всякое k-мерное линейное многообразие в может быть задано как множество линейных комбинаций, где параметры в i пробегают вещественную прямую, а? ортонормированный набор векторов
где евклидова норма, ? евклидово скалярное произведение, или в координатной форме:
Решение задачи аппроксимации для k = 0,1,...,n ? 1 даётся набором вложенных линейных многообразий
Эти линейные многообразия определяются ортонормированным набором векторов (векторами главных компонент) и вектором a 0 . Вектор a 0 ищется, как решение задачи минимизации для L 0:


В итоге получается выборочное среднее:
Французский математик Морис Фреше Фреше Морис Рене (Frйchet Maurice Renй) (02.09.1878 г. - 04.06.1973 г.) - выдающийся французский математик. Трудился в области топологии и функционального анализа, теории вероятностей. Автор современных понятий о метрическом пространстве, компактности и полноте. Авт. в 1948 году обратил внимание, что вариационное определение среднего, как точки, минимизирующей сумму квадратов расстояний до точек данных, очень удобно для построения статистики в произвольном метрическом пространстве, и построил обобщение классической статистики для общих пространств, получившее название обобщённого метода наименьших квадратов.
Векторы главных компонент могут быть найдены как решения однотипных задач оптимизации:
1) централизуем данные (вычитаем среднее):
2) находим первую главную компоненту как решение задачи;

3) Вычитаем из данных проекцию на первую главную компоненту:
4) находим вторую главную компоненту как решение задачи

Если решение не единственно, то выбираем одно из них.
2k-1) Вычитаем проекцию на (k ? 1)-ю главную компоненту (напомним, что проекции на предшествующие (k ? 2) главные компоненты уже вычтены):
2k) находим k-ю главную компоненту как решение задачи:

Если решение не единственно, то выбираем одно из них.

Рис. 4
Первая главная компонента максимизирует выборочную дисперсию проекции данных.
Например, пусть нам дан центрированный набор векторов данных, где среднее арифметическое значение x i равно нулю. Задача? найти такое отртогональное преобразование в новую систему координат, для которого были бы верны следующие условия:
1. Выборочная дисперсия данных вдоль первой координаты (главной компоненты) максимальна;
2. Выборочная дисперсия данных вдоль второй координаты (вторая главная компоненты) максимальна при условии ортогональности первой координате;
3. Выборочная дисперсия данных вдоль значений k-ой координаты максимальна при условии ортогональности первым k ? 1 координатам;
Выборочная дисперсия данных вдоль направления, заданного нормированным вектором a k , это
(поскольку данные центрированы, выборочная дисперсия здесь совпадает со средним квадратом уклонения от нуля).
Решение задачи о наилучшей аппроксимации даёт то же множество главных компонент, что и поиск ортогональных проекций с наибольшим рассеянием, по очень простой причине:
и первое слагаемое не зависит от a k .
Матрица преобразования данных к главным компонентам строится из векторов «A» главных компонент:
Здесь a i -- ортонормированные векторы-столбцы главных компонент, расположенные в порядке убывания собственных значений, верхний индекс T означает транспонирование. Матрица A является ортогональной: AA T = 1.
После преобразования большая часть вариации данных будет сосредоточена в первых координатах, что даёт возможность отбросить оставшиеся и рассмотреть пространство уменьшенной размерности.
Самым старым методом отбора главных компонент является правило Кайзера , Кайзер Иоганн Генрих Густав (Kaiser Johann Henrich Gustav, 16.03.1853 г., г.Брезно, Пруссия - 14.10.1940 г., Германия) - выдающийся немецкий математик, физик, исследователь в области спектрального анализа. Авт. по которому значимы те главные компоненты, для которых
то есть л i превосходит среднее значение л (среднюю выборочную дисперсию координат вектора данных). Правило Кайзера хорошо работает в простых случаях, когда есть несколько главных компонент с л i , намного превосходящими среднее значение, а остальные собственные числа меньше него. В более сложных случаях оно может давать слишком много значимых главных компонент. Если данные нормированы на единичную выборочную дисперсию по осям, то правило Кайзера приобретает особо простой вид: значимы только те главные компоненты, для которых л i > 1.
Одним из наиболее популярных эвристических подходов к оценке числа необходимых главных компонент является правило сломанной трости , когда набор нормированных на единичную сумму собственных чисел (, i = 1,...n) сравнивается с распределением длин обломков трости единичной длины, сломанной в n ? 1-й случайно выбранной точке (точки разлома выбираются независимо и равнораспределены по длине трости). Если L i (i = 1,...n) - длины полученных кусков трости, занумерованные в порядке убывания длины: , тогда математическое ожидание L i:

Разберём пример, заключающийся в оценке числа главных компонент по правилу сломанной трости в размерности 5.

Рис. 5.
По правилу сломанной трости k-й собственный вектор (в порядке убывания собственных чисел л i) сохраняется в списке главных компонент, если
На рисунке выше приведён пример для 5-мерного случая:
l 1 =(1+1/2+1/3+1/4+1/5)/5; l 2 =(1/2+1/3+1/4+1/5)/5; l 3 =(1/3+1/4+1/5)/5;
l 4 =(1/4+1/5)/5; l 5 =(1/5)/5.
Для примера выбрано
0.5; =0.3; =0.1; =0.06; =0.04.
По правилу сломанной трости в этом примере следует оставлять 2 главных компоненты:
Следует только иметь в ввиду, что правило сломанной трости имеет тенденцию занижать количество значимых главных компонент.
После проецирования на первые k главных компонент с удобно произвести нормировку на единичную (выборочную) дисперсию по осям. Дисперсия вдоль iй главной компоненты равна), поэтому для нормировки надо разделить соответствующую координату на. Это преобразование не является ортогональным и не сохраняет скалярного произведения. Ковариационная матрица проекции данных после нормировки становится единичной, проекции на любые два ортогональных направления становятся независимыми величинами, а любой ортонормированный базис становится базисом главных компонент (напомним, что нормировка меняет отношение ортогональности векторов). Отображение из пространства исходных данных на первые k главных компонент вместе с нормировкой задается матрицей

Именно это преобразование чаще всего называется преобразованием Кархунена-Лоэва, то есть собственно методом главных компонент. Здесь a i -- векторы-столбцы, а верхний индекс T означает транспонирование.
В статистике при использовании метода главных компонент используют несколько специальных терминов.
Матрица данных , где каждая строка - вектор предобработанных данных (центрированных и правильно нормированных), число строк - m (количество векторов данных), число столбцов - n (размерность пространства данных);
Матрица нагрузок (Loadings) , где каждый столбец - вектор главных компонент, число строк -- n (размерность пространства данных), число столбцов - k (количество векторов главных компонент, выбранных для проецирования);
Матрица счетов (Scores)
где каждая строка - проекция вектора данных на k главных компонент; число строк - m (количество векторов данных), число столбцов - k (количество векторов главных компонент, выбранных для проецирования);
Матрица Z-счетов (Z-scores)

где каждая строка-- проекция вектора данных на k главных компонент, нормированная на единичную выборочную дисперсию; число строк - m (количество векторов данных), число столбцов - k (количество векторов главных компонент, выбранных для проецирования);
Матрица ошибок (остатков ) (Errors or residuals)
Основная формула:
Таким образом, Метод главных компонент, один из основных методов математической статистики. Основным предназначением его является разграничение между необходимостью исследования массивов данных при минимуме их использования.
Исходной для анализа является матрица данных
размерности
 ,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям
,
i-я строка которой характеризует i-е
наблюдение (объект) по всем k показателям .
Исходные данные нормируются, для чего
вычисляются средние значения показателей
.
Исходные данные нормируются, для чего
вычисляются средние значения показателей ,
а также значения стандартных отклонений
,
а также значения стандартных отклонений .
Тогда матрица нормированных значений
.
Тогда матрица нормированных значений

с
элементами

Рассчитывается матрица парных коэффициентов корреляции:

На
главной диагонали матрицы расположены
единичные элементы
 .
.
Модель компонентного анализа строится путем представления исходных нормированных данных в виде линейной комбинации главных компонент:

где
 -
«вес», т.е. факторная нагрузка
-
«вес», т.е. факторная нагрузка -й
главной компоненты на
-й
главной компоненты на -ю
переменную;
-ю
переменную;
 -значение
-значение
 -й
главной компоненты для
-й
главной компоненты для -го
наблюдения (объекта), где
-го
наблюдения (объекта), где .
.
В матричной форме модель имеет вид

здесь
 - матрица главных компонент размерности
- матрица главных компонент размерности ,
,
 -
матрица факторных нагрузок той же
размерности.
-
матрица факторных нагрузок той же
размерности.
Матрица
 описывает
описывает наблюдений в пространстве
наблюдений в пространстве главных компонент. При этом элементы
матрицы
главных компонент. При этом элементы
матрицы нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что
нормированы, a главные компоненты не
коррелированы между собой. Из этого
следует, что ,
где
,
где – единичная матрица размерности
– единичная матрица размерности .
.
Элемент
 матрицы
матрицы характеризует тесноту линейной связи
между исходной переменной
характеризует тесноту линейной связи
между исходной переменной и главной компонентой
и главной компонентой ,
следовательно, принимает значения
,
следовательно, принимает значения .
.
Корреляционная
матрица
 может быть выражена через матрицу
факторных нагрузок
может быть выражена через матрицу
факторных нагрузок .
.
По
главной диагонали корреляционной
матрицы располагаются единицы и по
аналогии с ковариационной матрицей они
представляют собой дисперсии используемых
 -признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы
-признаков,
но в отличие от последней, вследствие
нормировки, эти дисперсии равны 1.
Суммарная дисперсия всей системы -признаков
в выборочной совокупности объема
-признаков
в выборочной совокупности объема равна сумме этих единиц, т.е. равна следу
корреляционной матрицы
равна сумме этих единиц, т.е. равна следу
корреляционной матрицы .
.
Корреляционная матриц может быть преобразована в диагональную, то есть матрицу, все значения которой, кроме диагональных, равны нулю:
 ,
,
где
 - диагональная матрица, на главной
диагонали которой находятся собственные
числа
- диагональная матрица, на главной
диагонали которой находятся собственные
числа корреляционной матрицы,
корреляционной матрицы, - матрица, столбцы которой – собственные
вектора корреляционной матрицы
- матрица, столбцы которой – собственные
вектора корреляционной матрицы .
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения
.
Так как матрица R положительно определена,
т.е. ее главные миноры положительны, то
все собственные значения для любых
для любых .
.
Собственные
значения
 находятся как корни характеристического
уравнения
находятся как корни характеристического
уравнения

Собственный
вектор
 ,
соответствующий собственному значению
,
соответствующий собственному значению корреляционной матрицы
корреляционной матрицы ,
определяется как отличное от нуля
решение уравнения
,
определяется как отличное от нуля
решение уравнения

Нормированный
собственный вектор
 равен
равен

Превращение
в нуль недиагональных членов означает,
что признаки становятся независимыми
друг от друга ( при
при ).
).
Суммарная
дисперсия всей системы
 переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений
переменных в выборочной совокупности
остается прежней. Однако её значения
перераспределяется. Процедура нахождения
значений этих дисперсий представляет
собой нахождение собственных значений корреляционной матрицы для каждого из
корреляционной матрицы для каждого из -признаков.
Сумма этих собственных значений
-признаков.
Сумма этих собственных значений равна следу корреляционной матрицы,
т.е.
равна следу корреляционной матрицы,
т.е. ,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков
,
то есть количеству переменных. Эти
собственные значения и есть величины
дисперсии признаков в условиях, если бы признаки были бы
независимыми друг от друга.
в условиях, если бы признаки были бы
независимыми друг от друга.
В
методе главных компонент сначала по
исходным данным рассчитывается
корреляционная матрица. Затем производят
её ортогональное преобразование и
посредством этого находят факторные
нагрузки
 для всех
для всех переменных и
переменных и факторов (матрицу факторных нагрузок),
собственные значения
факторов (матрицу факторных нагрузок),
собственные значения и определяют веса факторов.
и определяют веса факторов.
Матрицу
факторных нагрузок А можно определить
как
 ,
а
,
а -й
столбец матрицы А - как
-й
столбец матрицы А - как .
.
Вес
факторов
 или
или отражает долю в общей дисперсии, вносимую
данным фактором.
отражает долю в общей дисперсии, вносимую
данным фактором.
Факторные
нагрузки изменяются от –1 до +1 и являются
аналогом коэффициентов корреляции. В
матрице факторных нагрузок необходимо
выделить значимые и незначимые нагрузки
с помощью критерия Стьюдента
 .
.
Сумма
квадратов нагрузок
 -го
фактора во всех
-го
фактора во всех -признаках
равна собственному значению данного
фактора
-признаках
равна собственному значению данного
фактора .
Тогда
.
Тогда -вклад
i-ой переменной в % в формировании j-го
фактора.
-вклад
i-ой переменной в % в формировании j-го
фактора.
Сумма
квадратов всех факторных нагрузок по
строке равна единице, полной дисперсии
одной переменной, а всех факторов по
всем переменным равна суммарной дисперсии
(т.е. следу или порядку корреляционной
матрицы, или сумме её собственных
значений)
 .
.
В
общем виде факторная структура i–го
признака представляется в форме
 ,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
,
в которую включаются лишь значимые
нагрузки. Используя матрицу факторных
нагрузок можно вычислить значения всех
факторов для каждого наблюдения исходной
выборочной совокупности по формуле:
 ,
,
где
 – значение j-ого фактора у t-ого
наблюдения,
– значение j-ого фактора у t-ого
наблюдения, -стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки;
-стандартизированное
значение i–ого признака у t-ого наблюдения
исходной выборки; –факторная нагрузка,
–факторная нагрузка, –собственное значение, отвечающее
фактору j. Эти вычисленные значения
–собственное значение, отвечающее
фактору j. Эти вычисленные значения широко используются для графического
представления результатов факторного
анализа.
широко используются для графического
представления результатов факторного
анализа.
По
матрице факторных нагрузок может быть
восстановлена корреляционная матрица:
 .
.
Часть дисперсии переменной, объясняемая главными компонентами, называется общностью
 ,
,
где
 - номер переменной, а
- номер переменной, а -номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
-номер главной компоненты. Восстановленные
только по главным компонентам коэффициенты
корреляции будут меньше исходных по
абсолютной величине, а на диагонали
будут не 1, а величины общностей.
Удельный
вклад
 -й
главной компоненты определяется по
формуле
-й
главной компоненты определяется по
формуле
 .
.
Суммарный
вклад учитываемых
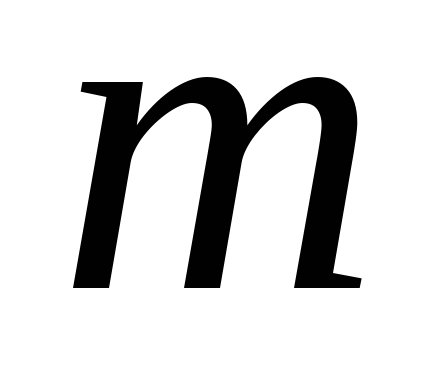 главных компонент определяется из
выражения
главных компонент определяется из
выражения
 .
.
Обычно
для анализа используют
 первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
первых главных компонент, вклад которых
в суммарную дисперсию превышает 60-70%.
Матрица факторных нагрузок А используется для интерпретации главных компонент, при этом обычно рассматриваются те значения, которые превышают 0,5.
Значения главных компонент задаются матрицей
